 T w e n t y S i d e d
T w e n t y S i d e d

The more I work with a team of people, the more I’m convinced that having open, accessible game data is the path of least resistance. Why make buggy, lame, proprietary in-house tools when you can just stick all the data into text files and let people use their text editor of choice? Why spend time and effort packing simple data into binary files when you can leave it in plain text? As long as the data isn’t binary in nature (text-based 3D models and sound would probably not be a good idea) then open files are a win for everyone: Easier for coders, more comfortable for the artists, and more mod-friendly for enterprising players.
Of course, I’ve always thought this way, but I assumed it was bias from all the years I worked at Activeworlds, which focused on user-generated content, similar to Second Life or Roblox. I often wondered if I’d gravitate towards obscured data if I ever found myself working on a “proper” game.
But no. But if anything, I’m more pro-“open data” than ever.
But what if the users edit their data files to cheat and give themselves a billion hitpoints?
Yeah. Not a concern. Stopping single-player cheating is a lot like stopping pirates: It can’t be done, but if you’re really creative and determined you can waste a lot of time and money trying.
Early in the project, I had a lot of stuff hard-coded. Certain gameplay parameters were set in stone, and you couldn’t change them without changing the source code and patching the game. That’s basically fine for a one-person team. When I’m working alone, it’s just as easy to change a bit of source code as it is to change some text file of game data. But once Pyrodactyl joined, more and more of the game migrated out of code and into text files the artists controlled.
The only downside is…
It takes HOW LONG to launch the game?

The game used to launch in well under two seconds. Over the past few months, that number has been creeping upwards. This week I noticed it topped ten seconds. That seems unreasonable. We’re certainly not processing five times as much data at startup.
If anything, the game should be loading a little faster than before. Originally all of the level geometry drew from a single gargantuan atlas texture, which contained the tilesets for every level in the game. This texture was always read at startup, which probably had some modest time cost. But one of the problems Arvind ran into with Unrest is that some craptops”Crappy Laptops”, which is our catch-all term for any odd non-gaming PC. Anything with a 4:3 display, integrated graphics, or older than the “Yo Dawg” meme ends up called a craptop. can’t handle textures over 2048×2048. So, we chopped up the scenery textures so it only loads one at a time.
So what’s causing this slowdown?
That’s a Really Good Question.
I’ve always said that Microsoft makes horrible software, except for their software to make software, which is absolute excellenceThe only faults of Visual Studio are its proprietary project files that are useless to Linux teams, and the fact that it’s (somewhat understandably) tied to Windows.. When I left Activeworlds, I lost access to the corporate license of Professional Edition of Visual Studio and had to switch to the Hippie Freeloader Edition. (Called “Express”. Because nothing speeds your progress like missing features.)
It’s still great, but it was missing a good profiler. Profiling tools analyze the program as it runs, and show you where all the CPU cycles are going. It’s not something you need every day, but when you need it you really need it.
This year – in a mad fit of behavior so un-Microsoft it’s borderline suspicious – they began offering the super-premium version to the public, for free. So I have access to profiling tools again. Let’s see what it says about Good Robot:

I guess I sort of gave it away in the intro, but the result was actually a surprise to me. I would have expected the time to go into loading bulky texture data. (Nope. Nearly instant.) Maybe loading the 70 different audio files that comprise the sound effects for the game? (Nope. Trivial.) Or maybe the bit of code that examines the individual sprites a pixel at a time so that it can do per-pixel hit detection? (Eh. That’s a little heavy, taking around 11% of the startup time. But it’s not the problem.) Launching the engine? (Trivial.) Loading the shaders? (So fast you basically can’t measure it.) Loading the interface? (Not really.)
But no. The long load times were the result of reading text files.
Almost 40% of the startup cost is spent in EnvInit (), which is nothing but text parsing. And it’s not even all the text parsing. There are other text parsers at work elsewhere. They’re doing more in less time, because those other parsers are working on XML!
For those that don’t know: XML files are like text files, except they’re huge and cumbersome and barely readable. My two favorite XML quotes are:
“XML is a classic political compromise: it balances the needs of man and machine by being equally unreadable to both.” â€" Matthew Might
“XML combines the efficiency of text files with the readability of binary files” â€" unknown
But I probably shouldn’t be chucking stones at the XML camp while I’m living in the glass house that is my own text parser. XML might be huge and ungainly, but the game is loading it far, far faster than the rest of our game data, which is in a far simpler format. A great deal of time is spent reading the weapons in do_projectile_inventory (). The weapons file is a minuscule 25k, and holds just 48 weapons. It’s ludicrous that it should take 17% of the startup time reading that file. In the time the game spends laboriously reading that file, you could probably read it in from disk and write it back out again a hundred times over.
In an ideal world, there would be a single clog somewhere, one bit of inefficient or malfunctioning code that’s being called hundreds or thousands of times. But this is not an ideal world, and it seems like the problem is smeared all over the place. The problem is that I’m using strings poorly.
Way back in 2010, I had a post about what a pain in the ass it is to have to manually manage the memory of strings of text. You have to do lots of fussy work to allocate memory and make sure you handle it just right. Something that could be done in 2 lines of code in another language might take six or seven to do properly in C. And if you messed up you’d waste memory, slow down your program, or crash. So it was a lot of work for a lot of danger.
But that’s not how today’s hip youngsters do things. No! They have C++, which comes with sexy new ways to handle text.
I’ve been gradually transitioning to the “new” way of doing things over the last few years. (“New” is a really strange term in programming. I might mean “since last week” or “since the mid-90’s”, depending on context.) But there’s a difference between learning to do something and learning to do it well. I haven’t learned – or even bothered to investigate – the common pitfalls of the new system.
As a result, my text parser was doing a ton of needless work. Something like this:
It’s time to compare two strings!
But we don’t care about upper / lowercase. So take the first string and MAKE A COPY OF THE WHOLE THING, then convert the individual characters to lowercase, then take the contents of the copy and overwrite the original.
We also don’t care about whitespace. If we’re comparing “Apple” and “Apple “, they should match, even though the second one has a bunch of spaces after it. So MAKE A COPY OF THE WHOLE STRING.
Now take that copy AND MAKE ANOTHER COPY, and pull the spaces off the end. Now MAKE ANOTHER COPY and pull the spaces off the beginning. Now give the new, cleaned-up version of the string back to the original.
Now do ALL of that to the second string.
THEN compare them.
That doesn’t sound that bad, right? Sloppy, yes. But, copying a few extra bytes a few extra times should be harmless on a modern computer.
Except, when you need to look for thing A in group B. If thing A is a zucchini and I need to look for it in the list of 48 different vegetablesAnd then have the search fail, because zucchini is a fruit., then I need to do that whole block of actions for every veggie until I find a match. As the list grows, the amount of extra copying can quickly get out of hand. The time cost can ramp up quickly, particularly in my implementation where I was frequently searching through lists within lists.
Does This Matter?

Well, not really. Not in the long run. This was something wrong, and it was wrong in an interesting and unexpected way, which is why I wrote about itI probably spent double the time writing this article than I spent investigating and solving the problem.. A ten-second load screen is not a horrible sin, and there are many games that take much longer to do much less.
But I’m also kind of picky when it comes to loading times, because loading slows down iteration and iteration is important. People love to say that “premature optimization is the root of all evil.”, but I think there’s a really good case for keeping the startup times snappy, particularly as team size grows.
Most of the people working on your game are probably not programmers. They’re artists. They’re making constant changes. Change the color. Add a few hitpoints. Swap out a new wall texture. Drop in a new sound effect. Tweak a particle effect. Replace a 3D model. You can’t make every part of the game editable while the game is running, which means your artists are going to be restarting the game often. In some cases, they might spend a majority of their time sitting and waiting for the game to start.
If you’ve ever tried to photoshop a large image on a crappy computer then you probably know what I’m talking about. It’s frustrating to have to wait a few seconds to see the results of every action. Just a two-second delay can be maddening. A ten second delay is even worse. It’s long enough to break your flow, but not long enough that you can (say) check Twitter or look for cat pictures. It’s a gap of dead time and it can kill creativity. I don’t know how other people respond, but when I have a lot of creative latency like this it really increases the odds that I’ll stop working as soon as it’s “good enough” instead of polishing things until it’s “great”.
Footnotes:
[1] ”Crappy Laptops”, which is our catch-all term for any odd non-gaming PC. Anything with a 4:3 display, integrated graphics, or older than the “Yo Dawg” meme ends up called a craptop.
[2] The only faults of Visual Studio are its proprietary project files that are useless to Linux teams, and the fact that it’s (somewhat understandably) tied to Windows.
[3] And then have the search fail, because zucchini is a fruit.
[4] I probably spent double the time writing this article than I spent investigating and solving the problem.
Shamus Young is a programmer, an author, and nearly a composer. He works on this site full time. If you'd like to support him, you can do so via Patreon or PayPal.
Stop Asking Me to Play Dark Souls!

An unhinged rant where I maybe slightly over-reacted to the water torture of Souls evangelism.
The Mistakes DOOM Didn't Make

How did this game avoid all the usual stupidity that ruins remakes of classic titles?
Revisiting a Dead Engine

I wanted to take the file format of a late 90s shooter and read it in modern-day Unity. This is the result.
The Biggest Game Ever

How did this niche racing game make a gameworld so massive, and why is that a big deal?
Diablo III Retrospective
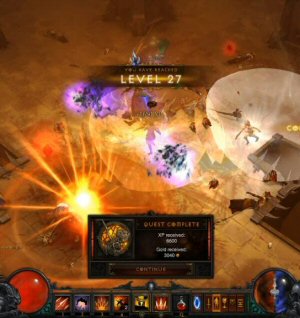
We were so upset by the server problems and real money auction that we overlooked just how terrible everything else is.
But what if someone steals your code and sells it as their own?You cant allow those lazy slackers earn easy money like that!
Well they wouldn’t be stealing the source code, only the data that loads into your code….which is pretty useless.
As if management knows the difference between two, or cares.
But they could change the data to modify the game completely until it’s a whole different game using your code. Modding is basically the same as stealing, right?
Yes, but, you’d still need to buy a copy of Good Robot to play that “whole different game.”
But you would only be able to sell the original game, not the modded one! That’s a net loss!
You’re joking, but Suits have been very successful at defining piracy (yarr) as theft.
In the same way they seem to be seriously considering trying to redefine mods to something where the rightsholders of the game are entitled to the rights of any modifications to that game, and so have the right to make money of it.
To quote a community rep from Paradox during the whole pay-for-Skyrim-mods debacle: “I’d love some way where modders can earn money, while we still get our cut.”. Naturally they already had their cut. They got it when both the modder and the mod-user bought the game. But they’re choosing not to see it that way.
From Paradox? You mean Bethesda?
No. Paradox had comments despite not being in on the debacle, probably because Paradox games are so extensively modded.
Paradox fanboy in me sees that sentence as “We don’t have a problem with moders getting paid for their work as long as we get our percentage, otherwise we are fine with free mods”.
And they would have to be mad, and they are not that, to in any way limit modding support in their games whose one of the main selling points is ridiculous level of moddability. Hell every time a dev diary comes out talking about some new feature or mechanic that will be introduced in a new patch or a new game like third comment is “will it be moddable” and the answer is almost allways YES.
Except Republics. Which has been no end of fun for the Crisis Of The Confederation mod, which is set in the science fiction future where women can hold elected office. Note that republics were in the second DLC, and the game had gender-equal succession in vanilla at launch. If you’re a Cathar, you can have a female archbishop lead your armies into battle while ruling as a queen who inherited in preference to your younger brother and none of your co-religionists will bat an eye, but you can’t have a woman get elected Doge even if her mother founded the republic.
That was more of a coding oversight rather than something done on purpose. The succession rules were always hard coded for efficency reasons, and in the process of setting up the Republic succession they forgot to account for female rulers. It was also fixed in a later patch if I’m not mistaken.
It hasn’t been fixed, at least not really. It’s possible to set the succession law to Absolute Cognatic when modding (though I don’t think you can in Vanilla), but it doesn’t really work. It’s impossible for a Doge’s daughter to get elected if unlanded. It’s impossible to make matralineal marriages except by event or targeted decision. You get extra trade posts from male family members in your court, but you can’t get them from female family members, not even via modding. I think they fixed some of the more insane failure modes like wrecking the republic screen so you can’t see trade posts and the family palace picture is replaced with your appropriate castle icon and clicking on it gets you a holding window with no buildings that reports zero gold and zero levies, but there’s still plenty of nonsense in there.
That’s not the only thing that’s annoyingly hardcoded, either. Apparently republic members of any culture all draw their portrait clothes from the same file, one of the many reasons the Warhammer mod doesn’t have Skaven, and they’re locked at having exactly five patrician families, and you can’t get trade posts as any non-Merchant Republic government except with trade routes.
For context, the game is originally intended to focus on playing a single feudal bloodline, and it supports playing asexual genetically engineered lizards who emerge fully-formed from glowing pools of liquid and are fanatically devoted to magical hibernating toads better than it supports matriarchal or gender-equal republics.
I dont mind if the original games developers get a cut for making an extremely mod friendly game.I do mind if they think they must get more money from any mod of their game,despite how easy/hard it was to do.
To be fair to Paradox, they’ve invested a great deal of time and effort into adding features specifically for modders; not only do they have stuff in editable text files, maybe half the things in their system aren’t even used in the base game and got added because modders requested it.
I wouldn’t have a problem with Paradox earning a cut from modders by curating a database and handling payment details. I wouldn’t even have a problem with them selling the mod tools separately.
Even worse, they will be able to unlock all the weapons without paying for the microtransaction. They’ll be able to double their health without buying the “die less” DLC. And they’ll be able to increase the loot drop rates so high that they ruin the economy of the real-money auction house. WHERE WILL IT END?!
Nail on the head there, I think. Modders are in direct competition with the publisher’s DLC.
I agree with you on open data file Shamus. If you are only making a single player game, what is the harm of having all your levels, items enemies stats defined by text files. Not only does it mean that it’s easy for you to find and edit aspect quickly, but it allows players to change things to their liking.
Can I ask, what sting implementation are you using?
You should probably be able to figure it out from the function call screenshot. Now I don’t program in C++ but it looks like he is sending strings as char pointers and is using functions from standard C++ library.
Ah, you’re right. Shamus is using std::string.
Juuust in case you ever want to have something like a highscore list and are concerned people might cheat, you could still have the code check something like the MD-5 sum of all concatenated text input files to test whether they’ve been modified. If they have, your highscore does not count or goes in a different list, and you can still go play the game whichever way you want.
Except that you shouldn’t use MD5, because it’s been broken since forever. Sure, it’s still too bothersome to rig up a working collision for most people, but that’s just giving a few other people a challenge. :P
I thought that it doesn’t matter if it’s cryptographically secure if you’re only using it has a checksum?
It matters if you want the checksum to be meaningful.
MD5 is broken completely: especially in a text document you can arbitrarily modify (by adding config keys the game ignores, by adding whitespace the game ignores, by changing the case of fields, …), you can easily (well, relatively) make the checksum be whatever you want to.
Which means that the checksum completely fails in what it’s meant to do: detect that the file was modified, as long as the file has been modified by someone who knows what they’re doing. For MD5, that barrier of entry isn’t even especially high.
Also, just to make it absolutely clear: DO NOT USE MD5 FOR ANYTHING ANYMORE. [1]
Even if you think “Oh, this is only an internal test thing”, it’s really better if you’re using something different from the start. For example SHA-2 [2], if you’re thinking about data integrity checks, or maybe even Keccak, the SHA-3 algorithm. If you’re doing password hashing, use scrypt and salt your passwords (and with an unique and strong salt per password!).
For non-cryptographic uses, djb2 is still reasonable, at least for short ASCII strings. Fowler-Noll-Vo and MurmurHash are the more modern alternatives.
[1] There are other uses for hashes than integetry checks (like string hashing for hashmaps), but MD5 was not designed for those purposes and isn’t particularily well-suited for them to begin with. You should have never used MD5 there anyway.
[2] Don’t use SHA-1 either! While not quite as broken as MD5, there has been a lot of breakthroughs in SHA-1 breaking lately, and it’s estimated that cracking SHA-1 is well within the reach of government-funded agencies today.
Don’t use md5 for anything that you care about if it’s cracked.
High score table in an offline game? Who cares.
But what if someone cheats and makes the top entry be “ASS – 999999 POINTS”?!Oh the robotity!
But if you don’t care, why hash the data at all?
Because you want that ASS person to earn their 999999 points,one way or the other.
Then why would you use a meaningless hashing algorithm to verify it when there are meaningful ones available for zero extra effort?
Put very simply, it’s only useful to check if something ISN’T what it’s supposed to be, but rubbish to check if something IS what it’s supposed to be.
If the md5 is off, you can be sure something is wrong. If the md5 is right, you can’t be sure if everything is ok. Getting the right md5 is near trivial, so a correct md5 becomes meaningless.
Even in the case of checking for random corruption (which by definition is not trying to fool you), does it have and serious advantages over better hashes? You’d have to be doing them pretty much every frame for speed to be an issue, surely?
I was going to reply that in the context of the game it’s not a super-serious application so who cares, but then, if there’s code available, there’s no reason not to do the more secure thing, and also just getting into the wrong habit or having that code at hand when you need a checksum for something more important is a thing.
=> I agree. Don’t use MD5. The more people keep using it the longer it’ll take to be replaced, and for the news (although not very new) of its brokenness to properly sink in.
Paradox has a similar checksum system, which compares only the config files that would let you cheat. This means that interface / graphical mods are completely OK, while gameplay mods will disable achievements / high scores. (There’s a common mod that adds a bazillion keyboard shortcuts for instance.)
As Shamus said – you can’t prevent single-player cheating, you can only spend a lot of time and effort failing. Sure, you can tell the game engine to do a checksum of all the text files and send that along with the high score to the server, but hackers have been modding binaries for decades now – they’ll just “fix” the checksum routine to always return the right value. Assuming they care enough to cheat, but as near as I can tell, someone always cares enough to cheat on high score lists. They’re pretty much useless.
Oh, this wasn’t meant as a way to prevent people from cheating!
It’s more meant as a way to prevent cheating people from accidentally showing up on leaderboards.
If somebody changes something in their config, would you require the player to remember that and avoid doing anything that might put them on a leaderboard, or wouldn’t it be nicer if the game realized it and just didn’t submit the scores, maybe giving the player a queue if and when appropriate?
-> If somebody wanted to, they could probably still make it but that would require a conscious and directed effort as opposed just forgetting that you multiplied all the weapon damage by ten last weekend.
Assuming you don’t need to distinguish between “projectile5” and “projectile 5”, skipping each ‘ ‘ character at the same time you’re converting ‘A’-‘Z’ to ‘a’-‘z’ and transferring everything else seems like it would skip a lot of the copying.
The problem was he was not processing the file character by character like a savage, but was using standard functions to do the work for him, and every time you call one of those they don’t perform the action on your memory but allocate a new memory location and send you the pointer to the modified copy. So over time these start to pile up.
I wasn’t completely clear on how you fixed this at the end. I take that you are doing all the transformations on the same string now, instead of creating a new copy for every transformation?
Also, what was the loading time after the change?
I assumed he was leading up to a follow-up article where he’d go over how he fixed this, since this one is pretty long to start with.
One thing I thought, which is probably dumb because I am, at least in terms of programming, is that he could have the text files and a tool to convert them into a binary, so that people only have to run the slow text-reading bit if they change something. Or even log the date modified on the files and check that quickly before converting anything that’s been fiddled with.
It wouldn’t be too hard to speed it up in a variety of ways. For example, calling ‘set two strings to lower case and remove all the spaces’ before every comparison could be done once at the start for the entire file. That would probably remove 90% of the delay.
How about parse and write to a binary file and then load from that? So then you can check for changes on the text files and only re-parse and re-generate the binary when needed.
This is a good idea. You could save a hash of the text file in the binary file and then compare them to quickly determine if the file had changed. (Much better than depending on a computer’s “last updated date” to determine change state.)
That is precisely why I recoiled in horror when I read this:
Does that mean you’re computing hitboxes anew every time the game starts, instead of just when the sprite atlas changes? That’s INSANE.
Except it apparently takes less than a second on a craptop, so… not.
The reason pixel-precise hit detection is usually avoided is because its a terrible idea to do it every FRAME. Precomputing the hitbox is how you get around that.
No, no. I build a giant array of bools for the whole 2048×2048 sprite sheet, indicating if individual pixels are visible or transparent. Then when a bullet enters (say) the sprite rectangle that makes up your head, the game looks in the table of bools to see if the bullet has hit an opaque pixel, or if it’s just passing through the space beside your head.
Presumably that gets optimized to a bitmap?
For fast lookup of data that maps directly to a contiguous integer index, it doesn’t really get any better than arrays, really. Doesn’t even matter much whether you use a jagged array out of a nested std::vector<std::vector<bool>>, or a bool[2048][2048]. Okay, I expect the latter to be faster by a slight margin, because when nesting std::vector there is an extra indirection at every nesting level; considering that it appears the size is always fixed and known beforehand, I’d probably choose bool[2048][2048]. But I see no benefit in turning that into a bitmap again.
Well, it would be a memory optimization. I remember coding on systems where a bool was stored as a 32 bit number (which was presumably more efficient speed-wise on a 32 bit system) and a 2048 by 2048 bool array would therefore be 16Mb, and the total RAM was smaller than that.
And for %deity%’s sake, don’t use std:vector
It’s (usually) implemented as a bitset, which is very space efficient – but incredibly slow.
Unless you really are memory-bound, don’t touch it.
On a modern desktop/laptop machine, just burn the RAM. You’ve got loads.
std:vector<bool>
(Don’t you just love HTML sanitisers)
And a startup option to ignore any version checking and updated from text files regardless …
That… is something I should probably look into, since I found that loading my own parametric files from compressed binary format took significantly(I don’t remember specific values) less time than the text files used to generate them.
For the time being, I was planning on only distributing the compressed binary files when I released my game, since the text files aren’t really designed for anyone who isn’t me to work with them…
Not only is that GIF mesmerizing, almost hypnotic – it also makes me feel like I will never achieve that level of skill in the game to dodge multiple missiles with such apparent ease…
It’s basically a matter of letting your brain learn it. You’ll fail a lot, but eventually you’ll get good at it and it becomes almost…. hard not to do it. Brains can learn to do a whole lot of stupid things.
…Like riding a bike? Maybe not stupid, but…
https://www.youtube.com/watch?v=MFzDaBzBlL0
…your brain is doing a lot more than you probably realize when you do it.
I love Smarter Every Day.
Similar to bike riding, have you ever thought about the act of reading?
As for your text file parsing problem, I am curious what did you do in the end. You really ended on a cliffhanger there.
Normalize the whole thing in a single pass (maybe even while reading?), so that you can do any naive comparisons with a mere == operator?
Write a custom comparison operator that requires no extra copies of either string?
Replace the (nested) lists with maps for faster lookup times?
Something else? All of the above?
(Personally, I would both do the normalization and storing the stuff in maps, then you don’t need a custom comparison operator anyway.)
I would assume it in part involves using whatever the C++ version of Java’s equalsIgnoreCase method is.
I think he left it as it is because he noted that it was a problem, but that he wasn’t certain he needed to fix it quite yet.
That is, it’s a problem that matters to others on the team, but if he doesn’t solve the problem itself, it’s not a game-breaking issue quite exactly.
Also, he might be exploring multiple solutions – you mentioned normalizing, whereas someone else mentioned making a binary parser to generate binary files for the game itself to read separate from the writing files.
The latter is probably not super ideal, however, since then instead of the waiting for it to boot up, it’s now moved to the waiting for it to do the parsing before you boot up.
The right way to do this kind of thing involves passing around references to whole strings and substrings (so you never actually copy anything), and tokenising as you go.
The tokenising is the big win – and will be why the XML parser was so much faster.
std:string is actually rather dumb and quite limited.
It’s much better than raw char pointers, if only because it manages the memory for you.
It needs appropriate “traits” to offer much.
Qt’s QString is implicitly shared (so it’s very cheap to pass around, even by value), and offers “QStringRef”, which is a pretty nice wrapper for a reference to a substring.
However, concatenating QStrings is rather slow – so you win some, you lose some.
boost has some very cool string handling as well.
I’d say that the optimization done now is not “premature”. You’ve identified a bottleneck, you have profiling data pointing to where the culprit is/was and you can (could?) compare before/after times.
Premature would’ve been doing all sorts of weird optimizations somewhere it wasn’t a problem (but might’ve been fun to make extremely fast, because cool coding).
Agreed, I don’t think it counts as premature optimisation if you’re optimising it because you know it’s slow in your actual use case.
Premature optimisation would be if he went through and tried to write the fastest version of his system before it was a problem.
Or in some cases, “before he knew it would eventually become a problem”.
I have, in some cases, optimised things heavily even before the first test run, because I could see it being called from within “the core”, so doing things like “choose a good data structure” and “pay attention to pre-calculate loop invariants, rather than computing the same value again and again inside the core of the loop” made sense even without profiling.
But on the whole, I much prefer “get it right, then get it fast”. Correctness matters. And if you have a known-correct implementation, you also have something you can test your optimised code against.
Yeah, he specifically mentions a bunch of places he thought might be slow. Trying to speed those up would have been premature.
One of the advantages that binary files have is that if you set it up right, much of the file won’t even need to be parsed, and you can use memory mapped files to skip even the copy-to-memory step.
To be fair, files created this way will be practically unreadable for a human. JIT file processing (use a human-readable file, but parse it to a quick-loading binary file the first time it’s used) might help both loading and artists, at the expense of the programmer.
“Map binary file straight in and use it” is OK as long as you never need to have references between things in the mapped file (if you do, you’d need to fix up the pointers on mapping the file) and as long as you never change the data structures (by having the exact binary layout on disk, you can no longer change any data structure’s in-memory representation, so you’re locked in to “the way it’s expressed in code” and possibly “your exact compiler version”) and to some extent machine architecture (this is probably less of an issue now, when most of the world is some shape of x86 derivative; this can also be worked around by massaging the binary blob(s) for different platforms prior to finalizing your distribution packaging).
This may well be a good way of shipping a final product, mind you. I would not (at all) be surprised if this is how vast chunks of console games are shipped.
As a highly professional Not-A-Programmer, this whole talk of loading times at startup reminds me of Space Pirates And Zombies. SPAZ begins with a loading screen that takes about 20 seconds on my quite good PC, but that loading screen contains an explanation that the game is preloading all art assets so that it doesn’t have to load them later (at a guess, it’s pulling data off an extremely large sprite sheet or set of sprite sheets rather than individual object textures). That explanation helps a lot with SPAZ’s “We’re just two dudes making an indie game because we care about it” credit.
Mind you, it loses a bit of credibility for implicitly promising only one loading screen, and then having another loading screen when you load a file. I’m pretty sure that what it’s actually doing is loading the galaxy map data as opposed to the texture data, and that the implicit promise of no more loading screens only refers to the loading of art assets rather than the loading of level data. I dunno.
I don’t see this as even an argument. Or, if it’s an argument, it’s about how to define the word “premature.”
In my job, I spend a lot of time convincing people to let go of things that aren’t important right now and focus on the things that are. I convince them “OK, we’re building a class that can add two integers as part of a larger process. Once you can add integers, let’s go back to the important process instead of teaching the class how to subtract, multiply, take square roots, etc.” Yes, we MIGHT need those features later, but if we don’t have a provable need for them now, let’s not add (ha!) them yet. You save HUGE amounts of time not speculatively adding (and maintaining) features and optimizations that “maybe we’ll need someday.” Build what you need.
A lot of those features that I advocate against fall into the “premature optimization” bucket. Sure, we could spend extra time writing the thing in a way that it’s optimally performant if we ever decide to spin up 2000 threads in parallel. But this is the process that loads the data dump we get daily in a batch overnight from our supplier. It runs once a day (twice if there’s a problem) and it runs overnight. And it only runs for 5 minutes as-is. Maybe optimizing performance of that time isn’t well spent.
But the rule for “do we need to work on this now?” ought to be “is it a problem now?” And if the answer is “yes, it’s a problem right now,” the now is the time to work on it. It’s not “premature” optimization, it’s the right time to focus on optimizing it.
Sure, it’s a small block of time, but (as you make an excellent case for) it’s a small block of time that happens ALL the time. Keep that fast.
Depending on the task it might be much easier to do something right the first time than it would to solve a problem you knew would occur after its a problem.
Not a programmer so I can’t come up with a good example, but if you know your game is going to include a lot of funky and intensive lighting and you don’t try and sort that out from the start, you might need to pull your whole engine apart to fix it later on?
I guess maybe ‘is it a problem now?’ can include problems that are highly likely to occur anyway.
But then with optimisation you might do something super finicky in advance that does t actually work well with what your finished product looks like
Yeah, it’s practically a law of the universe that it’s a lot easier to code things right the first time than to fix them later. So if you know in advance that you’ll eventually need to do something, doing it the moment you write the code it’s part of is the right call.
On the other hand, putting in effort to do things you don’t need to is an enormous waste of time, so if you don’t need to eventually do something, you shouldn’t do it. This is why you want to plan out projects as much as you can before you write a single line of code. That’s harder in game design because it’s an inherently iterative process, of course.
…assuming you understand the problem well enough to know the best way to solve it ahead of time, which isn’t always the case. Sometimes you only figure out the best solution by doing it once in a less than optimal way.
Exactly this.
I don’t dispute if there’s a known and immediate need for something, by all means do it the first time.
The thing I push back on is “I’m sure I’ll eventually need a framework for X” or “I could imagine someone eventually wanting a way to Y” and building support for that speculatively. The problem is that “eventually” often never comes.
And then you’ve incurred two costs. First, the cost of building something you didn’t actually need. Second, the cost of maintaining that code you never should have written forever. Someone coming in later to touch this class will have to parse and understand this code and what it does before they start. Someone refactoring the class will do work to avoid breaking this code because “someone’s probably using it.” When it’s finally time to retire your module years from now, someone will need to consider whether to port your speculative code – sometimes they’ll correctly assess the code isn’t used, sometimes they’ll get it wrong and bring it along.
Code lasts a long time. The moment it’s written, you start paying mainainence costs on it, and will continue to do so.
I’m reminded of the API rule of thumb – to make sure an API you provide gives sufficient access, you should build at least three different sample applications that make use of it. If you just build two or one, then chances are the API will be too specialized to those specific cases.
It’s true that software people far too often err on the side of adding in unnecessary functionality, and even if you build features in from the start there’s no guarantee that they’ll be the ones you need. Still, if you aren’t thinking of the scale in which code will be used, you’re leaving up to chance how badly it will need to be rewritten. That’s why our best practices are called ‘patterns’, the best you can hope for is to build exactly what you need right now while keeping an eye on the list of ways people usually screw up to avoid digging too deep of a grave. Pre-planning can help, but you’d need to know or have a way of finding out what you want to build and how that will change over the time spent building it.
I still like the analogy where human programmers are like blind painters.
“Not a programmer so I can't come up with a good example,”
Since I agree with this post, I will provide an example I’ve come across in the past. Specifically, with regards to SQL databases, but it similarly applies to file writing as well; once you’re working with data that’s live and written to a specification you’ve released, going back and changing how that data specification you wrote to fix something or to optimize the structure to not overly reference data you don’t need to always have, trying to add something to it or to change how something works in the database will run the risk of making all data made since you’ve released the first example completely unusable in the updated specification.
Planning around that possibility of how to migrate the data earlier on makes updating it much easier later.
Wanted to weigh in on this too :) This post is actually an example of optimization done right:
1 – Detect a performance problem exists: “It takes 10 seconds to launch.”
2 – Profile: “Hmm, text parsing is eating up a lot of time.”
3 – Apply fix.
4 – Check that the fix improves the situation.
A lot of people jump to 3 before doing 1 or 2 (and then never do 4). They might say “I’ll use this algorithm instead of this other one because it is better” while working, without knowing if the more complex algorithm actually solves a problem that exists in the program. Or they might detect a problem, decide that some piece is responsible without profiling, then focus on something that doesn’t actually impact that much. Imagine if you’d spent a week optimizing the sprite loading code, so it runs in half the time. It would be impressive, but wouldn’t actually impact the real problem.
Trying to optimize before you detect a problem, or before you identify the root of the problem, is premature optimization. It increases complexity, thus leading to bugs, and doesn’t result in a better product, which makes it evil.
And of course, you have to profile again after applying the fix to check that you improved the situation. This all seems obvious when spelled out, but the quote is popular because so many programmers don’t follow it.
On the other hand, if you initially plan to use a linked list for a rarely-updated list accessed in random locations and where every entry has a unique key, the appropriate time to say “no, that is a terrible idea, use a hash table” is before you write code that uses a linked list. That’s what pseudocode and runtime complexity calculation is for.
Doing it right the first time around is always the best thing to do :) But if someone got it wrong and used a linked list where some other structure would have been better, don’t just jump in to fix it. Your time is better spent on problems that exist. And to identify what problems exist, you need to profile. If the linked list is a problem, you’ll eventually reach it by order of benefit/cost analysis.
If you have a few “free cycles” to spare and want to grab low-hanging fruit, sure, waste them in prettifying the code. But be aware that you’re prettifying, not optimizing.
It’s still going to be easier to rewrite the code right after you finish it than when you’ve gone from writing your datastructures to beta testing. True, it might not be worth it, but if you’re concerned about that adding a unit test for performance under your estimate of a worst case and running it takes like ten seconds per function and can save days. I suppose that’s like profiling, except that you can do it much earlier in the process.
If it’s only going to hold ten items ever, obviously it’s not really worth the effort, but if it’s going to be used to store purchase records in a database for a company with a million customers, you absolutely should rewrite it the very moment you notice.
Maybe you should use a Boost.Program_options:
http://www.boost.org/doc/libs/1_59_0/doc/html/program_options.html
As you are using C++ maybe you’re already using Boost for something, so it would not add additional dependency to your program.
If your artists collectively save an average of at least five seconds of loading time more than a total of fifty times a day over the course a year, this handy XKCD suggests you were justified in spending a full day making your code more efficient (assuming artists’ time is worth as much as your time).
I’m guessing these changes didn’t take that long, so definitely not premature optimization.
This article reminds me of how Doom 3 made intensive use of human-readable files, coupled with a very robust parser.
To me this looks more like an algorithm complexity issue, more than bad string handling. If the algorithm complexity is O(n²) instead of say O(n), the time spent will grow as the quadrat of the number of elements. You can optimize each pass through the list, but it will only postpone the problem.
If you have to search the same list of elements many times, it can help making a hash table with an average O(1) lookup time instead.
A different approach, but of course complementary, is caching the result, and only parse the text files when they change.
As far as I’m concerned, the answer to all text parsing woes is YAML. It’s easily human readable, structured, and standardized, with widely available heavily-tuned parsing libraries. It gives you all the benefits of XML while minimizing the “totally unreadable” factor (better even than JSON).
I second YAML (with JSON as a second place). And I have to agree that you don’t want to reinvent the wheel here: there are plenty of libraries doing this stuff well.
The question about the libraries would involve the part of – are the libraries faster than the XML libraries?
XML files can be a pain but you can use something like this to edit them (I feel that it makes them a little easier to read / manage)
Microsoft XML Notepad
I’m sure there’s open source variations out there but since Microsoft is already offering it for free, why not?
I tend to hate inventory caps in games whether they’re slot based or “weight” based. So I tend to grab mods or hacks that remove them.
One thing I’ve run into that I wouldn’t have expected as my inventory swells to hundreds of items, is that processing inventory in some games can get laggy. Skyrim, and Fallouts 3 and New Vegas have this problem. I know that working through an array can take a bunch of operations but given that my computer as four cores, each capable of performing billions of operations per second, it has surprised me how long it can sometimes take to add a new item to an inventory of a mere few hundred items.
This gives me the inkling of an idea of what sort of potential problems they might have.
Maybe they didn’t bother to optimize inventory management because the weight limits were supposed to keep inventory limits down.
My guess would be that they don’t actually use an array. The number of items in your inventory doesn’t strictly speaking have a cap in those games, because there are weightless items. Arrays are of fixed size, because they preallocate a contiguous chunk of memory, so you can’t just use an array for an unbounded number of entries (and even if there’s a total bound, allocating enough for the max when you almost always use only 10% is inefficient). You need to use another datastructure if you want to grow dynamically. Java has ArrayList, which basically makes an array and puts data into it until it’s full, then makes a larger array and copies all your data to it, which mostly gives you array performance characteristics except for a massive performance hit when the array copy happens. However, usually it’ll add a lot of space at once, so if you have it take a long time twice in a row it’s probably not an ArrayList, or if it is they’re doing something unusual with their insertion pattern. Whatever they’re using probably gives them fast access but slow insertion, because they optimized looking at your inventory over adding items to it.
Thank you. Its been a distressingly long time since I’ve been able to play in back end languages. I didn’t know that about ArrayLists. Could you make it anticipate the need and enlarge the list as a background operation? Say when the Array gets to 80% of capacity, go ahead and perform the operation to expand when the CPU isn’t being used heavily?
Its been a while since i played. I don’t think it hangs up every single time I add or remove an item so there may be something like you describe going on here.
What’s usually done for things that need to expand is that you increase the size of the thing by a constant factor (usually “double the size”), that way you get approximately constant time to add things (on average). Of course this breaks down on a sufficiently small set of additions, as the one you happen to measure may well be one that requires another “allocate more memory, copy things” and thus taking much more time.
Usually the expansion is done when “adding one more would be too much”, as asynchronous copying and updating is surprisingly hard. It can be done, but there’s a small risk that some code somewhere will have a reference to the old thing you just released.
I think you could in theory, but then you have a multithreading issue, and if you edit an element in the starting array after it’s been copied, the code needs to make sure to go back and edit it in the copy. It might be theoretically possible to have edits and reads of parts of the array that have already been copied happen in the copy and others happen in the original, but that sounds both hard to write and high overhead. Additionally, it’s also quite possible that the list will get to 80% capacity and trigger the asynchronous copy but never get to 100% of the original, and then you waste a bunch of time and memory for no reason.
You can do it without the multithreading issue. It’s totally possible to build an ArrayList that copies to the new array on the fly (not asynchronously, but bit by bit with each insertion) to avoid the one big insert problem. Unfortunately, the resource costs of having to keep two arrays in memory and up-to-date can’t be gotten around.
I dunno, that sounds like it would wreck your performance on other tasks, particularly searches, because you have to go back and forth between two arrays.
As I said, “surprisingly hard”. :)
If you did it, you’d need to ensure that everything went through the proper API, then you could do things like flag “if you’re reading/writing before index N, you really need to go and do that in the enlarged copy” and make double-sure that you never store a pointer to anything inside the data structure.
Aaaand now I’m tempted to write an implementation of that in Go, because it would be interesting. But I shall be strong and resist.
Well, it’s probably a safe bet that they didn’t use a Java ArrayList in Skyrim…
That’s surprising. Given that the list you’re starting with (your inventory) is presumably already sorted, you should be able to do a simple binary search to check where to insert the new item. Assuming that getting the entry at any index in the list runs in constant time, that whole operation should run entirely in logarithmic time depending on the size of the list.
I can’t fathom what the hell is going on there. A few hundred items is peanuts, especially since doubling your inventory should only incur a constant increase in operations required.
Depends heavily on what data structure they’re using, though. Just finding where to put the thing isn’t the whole picture.
Important note: insertion or deletion(where you fill in gaps) in the middle of an array is O(n) or higher. Every entry past the point where you do the insertion or deletion must be moved. In general, datastructures which allow faster insertion/deletion do not permit constant-time access, or if they do they have other drawbacks. Linked lists allow constant-time insertion/deletion once you reach that point in the list, but have O(n) access times. Trees are generally O(log(n)) for both insertion/deletion and access. Hash tables approach constant-time insertion/deletion and access, but require reasonably distinct hash codes and are generally O(n) if you’re searching for something with an unknown hash code.
For arrays:
Read Nth eleemnt – O(1)
Insert in middle – O(N)
Insert at tail – O(1) [ or O(N), if the array is full and you need to copy ]
Delete in middle – O(N)
Delete at tail – O(1)
For linked lists:
Read Nth element – O(N)
Insert in middle – O(1) if you have a reference, O(N) if you need to get a reference
Insert at tail – O(N) if you don’t have the tail, O(1) if you do [ having a list header with head and tail pointers is a common optimisation, that makes a whole lot of things easier ]
Delete in middle – O(1) if you have a reference, O(N) if you don’t
Delete at tail – O(N) [ O(N) or O(1) for a double-linked list, depending on the list header opt. mentioned above ]
I used to have a web page with these sorts of stats for quite a few different data structures, but it disappeared.
Here’s one that’s still around
Ah, of course, I completely ignored that.
The most common usage for an inventory, I imagine, is to just show it, meaning that you have to get the entire list. This would be O(n) in a linked list or an array, so that doesn’t matter much. But if you needed to insert an item in an array-like structure, you’d have O(log n) search time and O(n) insert time while in a linked list, you have O(n) search time and O(1) insert time, so it’s probably preferable.
Of course, in the long run, the choice doesn’t really matter much as both are O(n) overall. It’s still odd that the system would choke at a few hundred items. Their comparison operators must just take a really long time.
This is one of those weird problems that crop up when you mod games. The original developer will end up with certain assumptions on what is possible, and program within those assumptions. More robust code can better handle situations outside those assumptions, but that code often comes with a small performance price and/or more developer time.
If the lag comes as you’re adding new items, the problem is likely from the hassle of making new arrays and copying the information over. Inventory lists have more data in them than might first appear, and the operation itself takes a bit. Processing power has been getting quicker, but memory management is still fairly slow. May also run hard into assumption problems. Making more inventory space might require moving all other assets in memory around, which would account for much more time.
If the lag is constant though, I’d guess that there’s an issue with not properly determining what can be seen at any one moment. Occlusion probably isn’t a big deal when the inventory list is small, but may be a big deal if it suddenly balloons, and the display isn’t coping with it.
So, how did you solve it?
From your description, it sounds like you used to do those string transformations for every comparison, so I assume you instead only do those transformations once for every string whenever it’s loaded in. I’m guessing you did some fancier stuff, too.
By the way, are strings in C++ uneditable or can you change them on the fly without having to make a copy? ’cause in Java, for example, you can’t change Strings, meaning that you create a new object every time you, say, remove spaces from it.
This is C++. Everything is editable by default. You can get a pointer to the text in the string class and edit it with your own code. It’s another one of those moments where C++ is both very powerful and very dangerous.
What use would a programmer have for being able to directly edit pointers like that (as in changing the actual characters of the pointer, which I assume is what you meant)? Seems like the gains would be minimal in nearly all cases as opposed to letting the system manage that stuff as normal, unless you’re actually writing a compiler or something really low level like that.
He’s saying that you change the values of a string, without needing to make a new string. Useful if it’s faster than making new strings, or you need to worry about memory. Java doesn’t let you do that.
As far as pointers go, all they are is numbers. Pointing an object to something else is as simple as changing the number value of the pointer. It’s very common, and what happens all the time in low level C++. It’s common not to do that when working in higher levels, because you want to assure that there’s no problems with the pointer pointing to erroneous things, but all of them still fundamentally work by pointing at different things.
Even arrays are accessed by using math. The pointer to the array points to the first thing in the array. You work down the line by taking the product of the size of the object and where you want to access. So if I want the third object down, I’d do (Pointer)+(Size*3). Or preferably go through some other process that makes sure I don’t have any errors accessing the wrong area.
It’s not possible in Java because the String class specifically forbids any extension to the class from editing the actual values; the StringBuffer and StringBuilder classes allow dynamic editing. They’re not themselves Strings because then you’d be able to pass them into a class that expects immutable Strings and break things. It’s done that way because quite often if you want a variant of the string you’ll also want to keep the original for use somewhere else.
Recently, I sped some of my Python code up by a factor of over 100 by just moving from a list of numbers that needed to be iterated over several times to a numpy array which can be used in mathematical operations as if it was a number, and by storing some little tiny data that was previously being recomputed on the fly, and re-using it.
Thank you, dear profilers! You are a miracle of technology, and I officially love you! There are a thousand different things I would have tried otherwise if the profiler hadn’t told me where to look.
The BioWare games have that. Neverwinter Nights was supposed to be highly moddable, so the model format MDL exists in 2 versions: binary and ASCII. The game’s executable parses the ASCII data into a structure that’s basically what the binary format consists of when loading. They kept that (mostly?) in sync for KotOR/KotOR2 and Jade Empire, but no idea how complete it is and if that’s accessible in any way. Of course, it’s meant as an easy to parse exchange format, and not to directly modify it with a text editor.
The commonly used .obj file format is a simple text file that contains vertex coordinates and a list of which vertices comprise a triangle (in essence vertex- and index-buffer). It also has some additional meta-info, but it is completely with a text editor (if you’re a masochist).
On that point: Many interchange formats for 3D CAD data and surface descriptions are text-based.
STEP is just loads of point coordinates which can combine to curves, which can combine to surfaces. At least for curves you can strip out the keywords and brackets, then copy/paste the thing in a spreadsheet and plot them.
IGES (which is a terrible thing for other reasons) uses splines and B-splines for surfaces. They’re defining rectangular non-planar surfaces in space by a bunch of parameters, then a bounding curve on each of those, defined as spline in the U/V space of each surface — all defined via some keywords and numbers. Knew a guy who had to write code to produce some of those. Poor fellow…
Interestingly, these are often the only formats that work for moving geometries between programs.
I recommend writing your own minimalistic stack machine that reads strings, and converts them to integers on startup, which are then interpreted with big switch-statements during run-time. Unlike hardware, you’re not limited to a few very basic operations (like ADD/LOAD), but you can do things like Do_Damage_To_Player, which takes one argument, which can either be a fixed number, or any function that reads a value from anywhere, like HP_Of_Self. That way, you can write your missile as “Damage: Self_HP”, parse that into two numbers, and execute that with code that’s nearly as fast as hardcoded.
Since you’re not using XML at that point, but a self-designed (super simple) language, you can usually also parse it in record time.
It seems like it’d make sense to just use an existing library for parsing. I definitely don’t think I’d write my own config files parser because 1) the existing library will likely be better optimized, and 2) writing a parser sounds boring and I’m lazy.
If not, I think the solution to the problem of making too many copies of a string just to throw them away is a StringBuilder? I don’t know a ton about C++ (only used it a bit in university; never done any real dev in it), but I think that’d be the solution I’d look at in a language like Java, for example.
“I've always said that Microsoft makes horrible software, except for their software to make software, which is absolute excellence.”
Man, I love Visual Studio. It’s the most beautiful thing. I’m a C#.NET developer, so I pretty much live in it. And I still don’t even know half the things it can do!
Sadly, at work, we’re going to have to start using Java for some things, because we’re moving to quite a bit of new e-commerce software that’s all Java-based… so at least part time I’m going to have to start using Eclipse instead of VS. I know a lot of people love Eclipse, and I’m sure I’ll get used to it soon enough, but it still feels a bit like a bad break-up. :)
The only problem I have with Visual Studio is that the MSVC compiler hasn’t had a the best C++11 support, and continues to have some unexpected weirdness pop up every now and then with templating.
I’ve also found that most of the code navigation tools are hideously broken in the version I get to use (which is the rather old MSVC2010)
“Where is this token used” is a pointless string-compare, so looking for “m_itemMap” pops up a million hits, instead of just the things of that name in this particular class.
The “who calls me” is pretty cool, but so slow that I never really use it.
I mostly use Qt Creator these days – although as I’m doing Win/Linux development, part of that is simply to get trivial cross-platform project files.
The MSVC compilers are really weird though. Such an odd mix of C89 and bits from every version of C++.
Eclipse is passable. Personally, I’m rather fond of Netbeans, although IntelliJ is also quite good if you can stomach proprietary code (which I have trouble with).
You have a double “it” below the green room screenshot(“It it was something wrong”).
Guessing it should be “If it”.
There is hope.
http://www.extremetech.com/extreme/187746-by-2020-you-could-have-an-exascale-speed-of-light-optical-computer-on-your-desk
Yes, its an article about future hardware but after all the stuff recently about the speed of progress slowing down, thought you might like this.
Of course, it would mean Shamus’ game loads in a thousandth of a second so he’s denied the chance to spot and perform an optimization. On the bright side, real time photorealistic rendering and hi fidelity physics courtesy of photons. And your art team won’t have disruptive load times impacting their iteration cycles.
I haven’t read the whole article, but….TECHNICALLY, all electronics work at the “speed of light.” The speed of light is, in fact, the speed at which electromagnetic waves propagate through a conductor.
Actually, no. The speed of propogation of an electrical signal through a conductor varies based on properties of the conductor, but is typically 50%-95% of the speed of light (and always slower).
In any case, the big benefit of using optics for signaling in a computer isn’t the speed at which signals propogate; it’s that signals don’t interfere with other signals nearby, and, non-inherently, that many proposed mechanisms waste much less energy on switching losses than transistors.
More precisely, electromagnetic fields propogate at the speed of light in their medium, and the speed of light in any physical medium is slower than the speed of light in a vacuum.
Using low-energy photons instead of electrons reduces heat load and reduces the distance required between components as compared to the relatively high-energy electrons we currently use.
Reminded me of this recent article on Destiny (Kotaku).
In particular the bit where they say it took them eight hours to open the editor, change a minute detail and test-play the game. This is mind-numbing to me.
MADNESS!
I just… I can’t… why would anyone… I mean…
MADNESS!
I am currently involved, on and off, with a project, where converting the assets to different platforms (mainly iOS and Android) takes about 4 hours each time…we are currently trying to sparate the assets from the main application and have them once for each platform, so they don’t have to be converted anymore, but this requires a serious rewrite of a good chunk of the code. We should have done this earlier, before it got out of hand…
Wait wait wait wait wait, wait, uh…
Zucchini are fruit?! What else have you been keeping from us, Mister Young?
Tomatoes. Tomatoes are also fruit.
The world just doesn’t make sense to me anymore.
*hurls entire refrigerator into the front yard*
Oh by the way, technically pumpkins are also fruit. Just thought you’d want to know since they’re going to be all over the place soon.
I never really bought the whole “tomatoes are fruit” thing. Regular humans used the words “fruit” and “vegetable” to mean “sugary plant thing” and “starchy plant thing”, but lazy scientists co-opted the words to mean “has seeds in it” and “doesn’t have seeds in it”. You know, instead of just making up new words that don’t conflict with normal everyday terms. :S
Melville makes the same point about whether whales are fish in Moby-Dick. The traditional meaning of “fish” had encompassed whales (and likewise analogous terms in other languages) since time immemorial. That Linnaeus had come up with a new definition for the term (a bare lifetime ago when Melville wrote) might matter for scientific taxonomy, but he didn’t have the right or the power to dictate common usage. Whalers weren’t claiming that whales didn’t breathe air or bear live young, those just weren’t the distinguishing criteria for “fish” in their vocabulary.
(To an astronomer, everything heavier than helium is a “metal”. But an astronomer who tried to insist on that definition in everyday life wouldn’t get much of a hearing.)
I’m reliably informed that there is no such thing as a fish.
What this actually means is that there are different families of ‘fish’, with no common fish ancestor – hardly more closely related to one another than they are to us.
The mix up about fruits and vegetables is really silly.It comes from trying to splice culinary definitions with botany definitions.In botany,anything with a seed is considered a fruit,so someone thought it would be cool if they ate a tomato as if they would an apple,and called it fruit.Because why not?
I read there was an actual case (in England? EDIT: nope!) where a couple hundred years ago a judge ruled that tomatoes had to be legally considered a vegetable for tax reasons, and that definition stuck ever since. Fruits were taxed one way and vegetables another and it had everything to do with sweet vs. savory instead of seed container or not-seed-container.
This wasn’t an internet source, though, so no citation. I don’t even remember if I still have the book where I read it.
EDIT: Oh, actually five minutes with Google found this link, which is probably what I vaguely remember reading about. So we have Justice Horace Gray to thank for all this.
I would disagree. The court’s ruling was simply upholding that the common meaning of the words were important for tax purposes, not establishing the meanings.
I’ll dissent and claim that text based data files for everything (including sounds, models and textures) might be a good idea. Source control systems are really good at merging text files together, and usually have no way of merging binary blobs. Letting two different programmers/artists/etc work on the same file seems like it would be a huge win in productivity as long as merging Does What You Mean[tm]. It usually works in programming, so why not design game asset files in a mergeable way?
Jonathan Blow wrote a blog post about using text for data files.
Yes, because the structure of a text file is simple, and there’s a small, meaningful textual “diff”. This does not exists for sound or pixel graphics, even if you put them into text files.
You make the mistake of confusing the representation, whether it’s 0xFFFFFFFF, “white” or 255, with the data that is represented.
For vector graphics, for example an XML-based like SVG, this makes sense. Again, highly structured, hierachical data. And a low-resolution, low-color image, like a cursor or an icon, okay, there’s XPM which does exactly that. The amount of data there is small enough.
But a high-res, high color pixel image? Think about how you’d represent a pixel graphic as a text file. RGBA, “0”-“255”, separated by a space, and each row separated by a line break? Congratulations, you just blown the file size 3 times, and the information is still not meaningfully readable in any way (even worse when it’s a compressed format, like JPEG or a DXT, a common texture compression algorithm).
So, now your artist, say, drew a line. Bam, this will create a huge diff, even greater than a binary diff would be. And it’s entirely meaningless to both you, and the source control. Or, say, the artist moves a bit of the image. Or applies gamma-correction, so now the whole image has all values increased up X. Yeah, the source control will choke on that.
And how would that work when merging the changes of two separate artists? When you edit an image, the edits very rarely stay local to a tiny region of the image, like they do for code. Instead, you apply transformation across huge parts, even the whole image. That can’t be automatically merged.
Basically, you would need to teach the source control what an image is, how you would diff it, follow changes, basically reinventing some weird kind of lossless video compression.
Of course, this still would fail with naturally compressed images.
It’s exactly the same with sound files, just in one dimension instead of two, and with only one value (or two for stereo files), amplitude, instead of 3/4, RGB(A).
Or, to maybe make it clearer: when you ZIP (or RAR) files, you generally noticed that text files, including source code, ZIP very well, right? While images and sounds do not. That’s because English text and C/C++/Java/… code is highly structure, with lots and lots of easy and obvious redundancies that a general purpose compressor can easily throw away. For video and sound, we have to do a lot of computation, and even then we can only compress sound losslessly by about 50%.
TL;DR: the issue with images and sounds in source control is not their binary representation, but the fundamental nature of image and sound data.
If I were in charge of structuring the repo for a game dev project (we may soon see why this should never EVER be allowed…) I would want each individual model in the game stored as its own file. Ideally grouped into logical hierarchies (for some value of “logical”). That way, each individual model can be modified on its own, while still keeping track of changes…
Some things should probably be kept as (structured) text, but things like textures are probably better off as some sort of image format (UNLESS they’re procedural textures, in which case text probably makes sense again).
Then have something that can build one or more data blobs in whatever format the game prefers from these representations (and have a build artefact thing that makes it “not necessary” to rebuild the blob(s) until at least one source file they depend on has changed). It would also be double-plus-good to be able to load the “version control” representation in the game, if that can be done, since it may genuinely lead to better “edit, run, look” cycles.
I’d leave the blobs out of the iteration repo and build them nightly or something to go to the QA guys. Otherwise you’d be rewriting the blobs for each change you make anyway. The artists can have a test mode that loads in individual files which have changed since last getting blobbed.
While textual representation might be a horrendous idea, I wouldn’t be at all surprised to learn that version control is one item in the massive toolbox that is photoshop.
In general, there’s not any use to have two artists work on the same model, or the same for a sound file. Instead, you’ll have each artist working on their own model, in their own separate files, then work afterwards to merge it with the entire project in a meaningful way. Easier, and closer to how people would work anyway.
Could you make a tool that took the human-readable text files and spent the time converting to a quickly-mahine-readable binary IFF the binary and text file had different timestamps?
> You can't make every part of the game editable while the game is running
Actually, that has been a holy grail of game developers for years, and some teams more-or-less achieve it on some projects. Back in 2008 (I think) I listened to a presentation on KRI conference, where some company described how they achieved the ability to update resources in developer’s version without any restarts. Their artists could just _copy a new texture into a folder_ and the game would reload this texture without delay.
Of course, writing such systems is a complex and time-consuming task, which is why people rarely go the whole hog with it (management would hardly approve wasting man-months on creating a system which “only” makes artists’ iterations faster!).
A simpler solution, which we used in some projects, is to store a reference to a resource in code as a pointer to real resource + resource name + some flag to describe if pointer still valid (actually, we used a slightly more complex index-and-passport system, but you can mostly just use std::weak_ptr for this). Then, when you access a resource through such reference, you check if the pointer is still valid, and if it is not (because it was reloaded and address changed), you can re-acquire the pointer from resource manager via stored resource name (or ID or whatever). We used this system to reload models, textures, scripted effects, localization and UI templates in runtime, and it really sped up iterations.
The engine that Naughty Dog wrote for Jak & Daxter (and was then re-used for the first three Ratchet & Clank games) could not only dynamically change assets in the game, they could dynamically patch the code run-time.
I’ve read about such techniques, and Visual Studio even supports a flag “Allow hot-patching” which leaves a few bytes at the beginning of every function empty, so you could stick a jump into replacement function. However, I don’t see the appeal for a common situations, unlike reloading resources. Just preparing new code for hot-patching would probably take more time on modern machine than re-compiling the game with a fix. Of course it’s still useful when you’re hot-patching running OS service, but that’s not for everybody :)
I could see it vastly simplifying debugging in a video game by letting you repeatedly test new iterations on something halfway through a level without having to set up a special debug skip mode if you have a checkpoint system.
Oh, the temptation that is std::string. I know it well, hand back in ca . 2005 I worked on a title for the original Xbox with a bunch of programmers who were not aware of what goes on behind the scenes of that class. As a result, the game was doing tons of work comparing resource identifiers that were strings, and copying them around lots of times, on a machine with little memory and poor access speeds. Just making all those ids into integers must have halved our CPU load. Morale: it pays to have had the experience of managing strings by yourself in good old plain C, because you learn to fear them.
That sounds like a job for an enumerated type!
Not if you want to dynamically add new objects.
So… How long does it take to start up now that it’s fixed?
Hah! that is not a surprise to me. One time I made a simulation (academic stuff) and the data was being written to text files and read from them. Such a bad idea. In my case it was particularly obvious because it was a stupid amount of data, enough to freeze my computer. Overnight a textfile would go over 1 GB.