 T w e n t y S i d e d
T w e n t y S i d e d
Last time we left off, I had created a very simple program for loading in a big ‘ol wad of terrain data and rendering it in painful, CPU-killing detail. This time I’m going to be adding code to cut down on the number of polygons drawn. Here is how the terrain looked last time:

Right now it’s rendering about half a million polygons, which is a grotesque waste of rendering power. There are way too many polygons, most of which we could do without. So how to simplify? There are any number of open-source solutions, but since the goal of this project is to write my own terrain engine from scratch, I’m going with this system as explained by Peter Lindstrom. It’s titled Terrain Simplification Simplified: A General Framework for View-Dependant Out-of-Core Visualization. Despite making the claim of simplicity twice in the title alone, this stuff is, in fact, quite tricky to grasp. Maybe the claims of simplicity are just dry humor. Or maybe I’m just dense. Either way, this stuff was brain-busting for me.
The goal here is to reduce flat areas into few polygons, and keep complex areas (slopes) more high-polygon.
The problem is that you need to smoothly transition from high-poly in one area to low-poly in another. If you don’t, there will be little gaps in the terrain between high and low detail areas. The background (the blue sky, in this case) will shine through the gaps.
But how do you do this? Imagine a piece of paper. On the left half of the paper you have dots an inch apart. On the right, the dots are two inches apart. Now, connect all the dots in such a way that you make only triangles, and that you use the fewest number of triangles possible. If you work at it for a while, you’ll do it. Now: Same piece of paper, except it’s 512 inches wide and 512 long. Some spots have dots an inch apart, others have dots 2 inches, others have dots every 4, 8, 16 or 32, or even 64 inches. Now try making the right triangles.
The secret here is a quad tree. This is a great way to handle a large grid of data, which is what I’m up to.
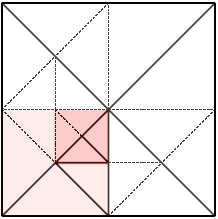
| To use a quad tree, our grid must be a perfect square. It has to have the same width and height, and they must be a power of 2. In the terrain I’ve been using, the width and height is 512, which is 29. For our example here, let’s assume we’re working with an 8×8 grid, which is 23. |  |
| The main grid is divided into 4 quadrants. So, we have this sub-grid of 2 x 2. Then… |  |
|
…each of those squares is, in turn, divided into 4 quadrants. This yields a sub-grid of 4 x 4, which in turn can be divided further, and so on.
Anyway, this gives us a way to look at the grid at different levels of detail. |
 |
| My program starts at the largest blocks on the 2 x 2 grid. Let’s say it examines the four blocks in question and determines that the lower-left one is a bit hilly, and needs to be divided further. The other three quadrants are flat enough that they can be left alone. So, we divide the lower-left block. |  |
| Within that block, we have 4 smaller blocks, and of those 4, we determine that the upper-right has some detail that needs to be preserved, but the other 3 are again simple enough that they can be left alone. Once again, we divide the one block into 4 smaller ones. |  |
|
Now for the magic. My program knows where the interesting detail is on the terrain, and what areas are flat and should be left simple. But how do I turn this into triangles?
The great thing about programming is that you can still follow a given set of directions and get to where you’re going, even if you don’t understand how to get there. By following the proceedures described in the Lindstrom article, I was able to get the triangulation to happen. However, I couldn’t actually understand it until I was done. This was an amazing moment. I didn’t know how to do it until after I’d done it. Strange. The is one of those concepts where I wonder how someone thought of it in the first place. I can only conclude that they must be a good bit smarter than me. |
 |
It took most of last weekend to sort out these ideas and distill them into code. Still, the results are impressive:

The upper-right side of the image is of the unoptimized terrain. The lower-left is of the exact same view using the polygon-reduction system. Note that when viewed solid, and not wireframe as they are here, these two would look almost identical. That is, I’ve only sacrificed a tiny bit of visual quality. So how much did I save?
The new terrain is 158,000 polygons. So, I’ve removed an amazing two-thirds of the polygons from the scene.
There is obviously a tradeoff at work here. I can sacrifice visual quality for polygon reduction. If I’m too agressive, small hills and other details will vanish altogether, and the scenery will look bland. However, I’m not at the point where I want to start tuning it just yet.
Looking at all of this wireframe is getting dull. Let’s make it solid and add some lighting.

By turning my optimizations off, I can now confirm that the optimized and non-optimized views are so similar that it isn’t even worth adding more screenshots to show the differences: they really do look almost the same.
Shamus Young is a programmer, an author, and nearly a composer. He works on this site full time. If you'd like to support him, you can do so via Patreon or PayPal.
Netscape 1997
What did web browsers look like 20 years ago, and what kind of crazy features did they have?
A Telltale Autopsy

What lessons can we learn from the abrupt demise of this once-impressive games studio?
Secret of Good Secrets

Sometimes in-game secrets are fun and sometimes they're lame. Here's why.
Dead Island

A stream-of-gameplay review of Dead Island. This game is a cavalcade of bugs and bad design choices.
Internet News is All Wrong

Why is internet news so bad, why do people prefer celebrity fluff, and how could it be made better?
Do you have a brief outline of the source used in the LOD subdividing system presented here?
I am not looking for anything that specifies where to subdivide; or the entire source code; just a simple subdividing rendering example where the flat areas contain less polygons, and the hilly areas contain more..
Thanks,
DEAR
The Lindstrom article isn't available at the specified URL, but there's a (probably simpler) article on the same technique at Gamasutra.
very usefull…
but will be perfect if source code is available for each part, besides explaining the algorithm instead of the result.
Could the code be available for download?
The Lindstrom paper is now available here http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.14.4771&rep=rep1&type=pdf
And Lindstrom’s list of publications:
http://people.llnl.gov/lindstrom2